Rearchitecting Apache Pulsar to handle 100 million topics, Part 1
Tags: pulsar-ng- Context
- Design approach
- Proof-of-concept design goal: 100 million topic inventory with high availability
- High level solution
- Metadata shard
- Summary of Part 1
Context
Welcome to read about the possible design for rearchitecting Apache Pulsar to handle 100 million topics.
The previous blog posts in this series have been about stating the problem.
- A critical view of Pulsar’s Metadata store abstraction
- Pulsar’s namespace bundle centric architecture limits future options
- Pulsar’s high availability promise and its blind spot
Pulsar’s promise of high availability with predicable read and write latency is vague. In reality, there’s a blind spot in Pulsar in the way how topics are moved from one broker to another during Pulsar broker load balancing and graceful shutdown of a broker. This causes unpredictable read and write latency, which conflicts with the promise.
It is disputable that Pulsar supports “millions of independent topics and millions of messages published per second”. Achieving “millions of independent topics” is not documented in the project, and there aren’t public demonstrations of this. One of the challenges are the scalability limits with Pulsar metadata handling. The goal of PIP-45 was to be able to replace Zookeeper with another metadata and coordination backend and increase the limits. This attempt has failed to deliver such results. PIP-45 has delivered other significant improvements, but it hasn’t been effective in addressing the scalability problem.
Design approach
“We cannot solve our problems with the same thinking we used when we created them.”
— Albert Einstein
In the mailing list, there was a lot of discussion that we must be careful to not break compatibility with existing Pulsar client. That makes sense and it is very important to support existing Pulsar clients. If we’d design a system that breaks compatibility, it wouldn’t be called Pulsar anymore.
I think that it’s a limiting factor if we are too cautious to remove and replace components and solutions from the existing Pulsar architecture. By now, improving Pulsar has happened incrementally without removing features or making significant changes to how Pulsar works under the covers.
My goal is to teach about the possibilities that there are for solving the problems stated in the previous blog posts. I don’t have a solution available that will be ready. Design is emergent and it evolves. We can make it better over time. The whole Pulsar community is needed in making the possibilities an actual reality. This blog post is just the beginning.
Proof-of-concept design goal: 100 million topic inventory with high availability
I have a goal to demonstrate that it’s possible to have a Pulsar cluster with 100 million topic inventory. The proof-of-concept might have gaps, and the goal isn’t to show a perfect system. The PoC will also be performed with limited scope. For example, I don’t have the goal to demonstrate with 100 million active topics, since the PoC could be very expensive and complex to perform with 100 million active topics. There will be 100 million topics in total, and a subset will be active. That should be sufficient for the PoC.
There will also be multiple phases in the PoC. Optimally, there would also be proof that the availability issue with topic unload / moving across brokers can be solved together with addressing the scalability problem. It’s always possible that the PoC fails because of some obstacle. If it fails, let’s lower the bar or find ways around the challenges. I’m confident that we will be able to reach the goals with the architecture models that I’m presenting here. This isn’t a complete explanation and there will be more blog posts on the way to cover all gaps. The 100 million topic inventory goal is useful so that we design for the future and go way beyond what is possible in today’s Pulsar architecture.
High level solution
Form follows function
A solution describes the intended functionality, behavior and the architecture that realizes this. It is more than just this, since architecture is about describing the decomposition into entities, describing the abstractions and defining the boundaries of the system.
There are multiple schools of software architecture design. I tend to follow an approach where one of the guiding principles of design is “form follows function”.
“Form follows function” has the roots in building architecture (functionalism, to be more specific).
For me in software, this principle means that design should focus on the core essence of what the system should achieve, the intended function of the system. The form, the structure and architecture, should emerge incrementally while the participants designing, delivering and using the system learn and understand more about the function and true purpose of the system over time. It is not about big upfront design. Let’s say that there should be just enough architecture at each iteration when developing a system. Once we understand “function”, we can come up with the “form” for delivering the functionality. This cycle is iterative and incremental, where the feedback from implementation, operations and use of the system guides the further design and formation of the architecture.
The “function” in “form follows function” for me is more than just functionality, it’s also about the quality aspects of the system. I work for DataStax leading Streaming Customer Reliability Engineering. Our mission statement is “We serve real-time applications with an open data stack that just works”. For database, streaming and messaging systems, the “just works” part is the essential function. It’s a feature. Quality must be built-in with in the “form” too. It cannot be slapped on afterwards in some sort of stabilization phase. There’s a relation between the “form” and the “function”. The “form” of a system cannot be changed in a bug fix. I hope it could, but hope is not a strategy as we have learned in the Site Reliability Engineering book.
We need more holistic approaches to address the scalability and availability problems in Pulsar so that we can reach the level with Pulsar that it “just works”. I have clarified the scalability and availability challenges in the previous blog posts. The goal of this blog post series isn’t to solve the problems. It is to teach about the possibilities. Together we can make the leap from current state to the state that is possible. I hope you also get excited about these possibilities and join the Apache Pulsar community to make this a reality.
The concept of Pulsar
This is one way to explain the essential concept of Pulsar in one sentence: “Apache Pulsar is a highly available, distributed messaging system that provides guarantees of no message loss and strong message ordering with predictable read and write latency.“
Pulsar’s README file lists the main features:
- Horizontally scalable (Millions of independent topics and millions of messages published per second)
- Strong ordering and consistency guarantees
- Low latency durable storage
- Topic and queue semantics
- Load balancer
- Designed for being deployed as a hosted service:
- Multi-tenant
- Authentication
- Authorization
- Quotas
- Support mixing very different workloads
- Optional hardware isolation
- Keeps track of consumer cursor position
- REST API for provisioning, admin and stats
- Geo replication
- Transparent handling of partitioned topics
- Transparent batching of messages
One could argue that some of the listed features aren’t really features, but implementation details. This isn’t perfect, but it gives a good high level understanding of what is the core of Pulsar.
Expanding our first sentence with a clarifying sentence about the additional functionality that are part of the core Pulsar concept could help us find a way to capture the essential.
- Apache Pulsar is a highly available, distributed messaging system that provides guarantees of no message loss and strong message ordering with predictable read and write latency.
- The system is horizontally scalable to millions of topics with throughput of millions of messages per second.
- It is designed to be deployed as a hosted service with sufficient controls for multitenancy, authentication, authorization, resource quotas and different service levels.
Towards a possible high level architecture: keeping load balancing and metadata functions together
Instead of rethinking the whole architecture for Pulsar, it’s useful to focus on the Pulsar load balancing and metadata functions. The assumption is that Pulsar load balancing and metadata handling shouldn’t be separated, and there’s a benefit in keeping these together. When explaining the functions, this assumption becomes more credible, although the proof of this is a working system that realizes this type of design.
Instead of categorizing everything as “metadata”, in the “form follows function” design approach that could be considered as blindness to the actual functionality. That is why we’d better dig into the functions and functionality that “Pulsar load balancing and metadata” is really about.
Avoiding analysis paralysis: accepting that this isn’t complete and perfect
Optimally, we would spend more time describing the functionality of each part of the core concept of Pulsar. This way we would be understanding what is essential and being able to start thinking of solutions that address this.
Describing all details that are involved in the design could be a good exercise, but there’s also the risk of getting into analysis paralysis where we don’t know where to start. So let’s get started and accept that we won’t be perfect. Some of the descriptions in this blog post might not be well written and could be expressed in a complicated way. I hope you bear with me. Please provide feedback: questions and suggestions of how this could be all improved.
A lot of the descriptions expressed in these blog posts aren’t final. We can make changes when we notice that something didn’t make sense after all. Some parts of the blog post are at a very draft level of planning and contain raw ideas that need more work before it makes sense. I’m sharing the ideas since I think that only by sharing progress can be made. You will find mistakes here. This is a raw draft and it’s far from completion. Perhaps this will be good enough for the purpose of teaching about the possibilities?
Functions of Pulsar load balancing and metadata
Metadata related:
- Topic inventory
- Topic policy
- Tenant inventory
- Tenant policy
- Namespace inventory
- Namespace policy
At runtime:
- Coordination: topic is owned on a single broker a time
- Balancing the load across brokers
- Fail over for topics when a broker fails
- Querying new topics with a regex pattern for multi-topic consumers
New functionality that would be needed
- Topic search & pagination
- Tenant search & pagination
- Namespace search & pagination
New functionality that would be nice-to-have
- Renaming support for topics
- Renaming support for tenants
- Renaming support for namespaces
- Aliases for topics? (like symbolic links). Could be useful with renaming.
- Moving topic from namespace to another. Useful for splitting/merging namespaces.
- Moving namespace from tenant to another. Useful for splitting/merging tenants.
- Additional level of isolation for tenant names in a multi-tenant environment. Tenant names would be unique in the “cloud account” level.
Kafka has “KIP-516 Topic Identifiers” to address issues with names used as identifiers. That is preparation for supporting topic renaming.
There is also functionality that is essential which is related to operating Pulsar. It should be possible to increase the capacity of the Pulsar system seamlessly. There’s also the need to isolate workloads. This is also taken into account when coming up with the “form”, the architecture.
High level architecture
Here’s a high level deployment view architecture:

The major change to existing Pulsar architecture is that tenant, namespace and topic level metadata is not stored in Zookeeper. There’s a new component container called “metadata shard” which will replace Zookeeper for all tenant, namespace and topic level metadata.
On top of the metadata layer, there is an admin & lookup layer which would be handling topic lookups. For lookups, this is similar to what was available in Pulsar with the Pulsar discovery component, which could be used to federate multiple Pulsar clusters into one (more details in this issue discussion). In the case where there’s no need to scale beyond one cluster, the admin & lookup layer doesn’t have to be separated. Instead, the brokers of the cluster could serve the role of the admin & lookup layer, as it is done in existing Pulsar brokers architecture.
One reason to make this change in the architecture is to have a way to scale a broker system seamlessly. Zookeepers will continue to be used for Bookkeeper metadata. The high level architecture doesn’t yet make a decision on whether to store Pulsar Managed ledger metadata to the Metadata shard or to Zookeeper.
The solution could be expanded to have yet another level of indirection where there would be a possibility to scale beyond a single metadata shard layer. This might be useful in certain cloud provider use cases where stronger forms of isolation are needed because of security or policy reasons.
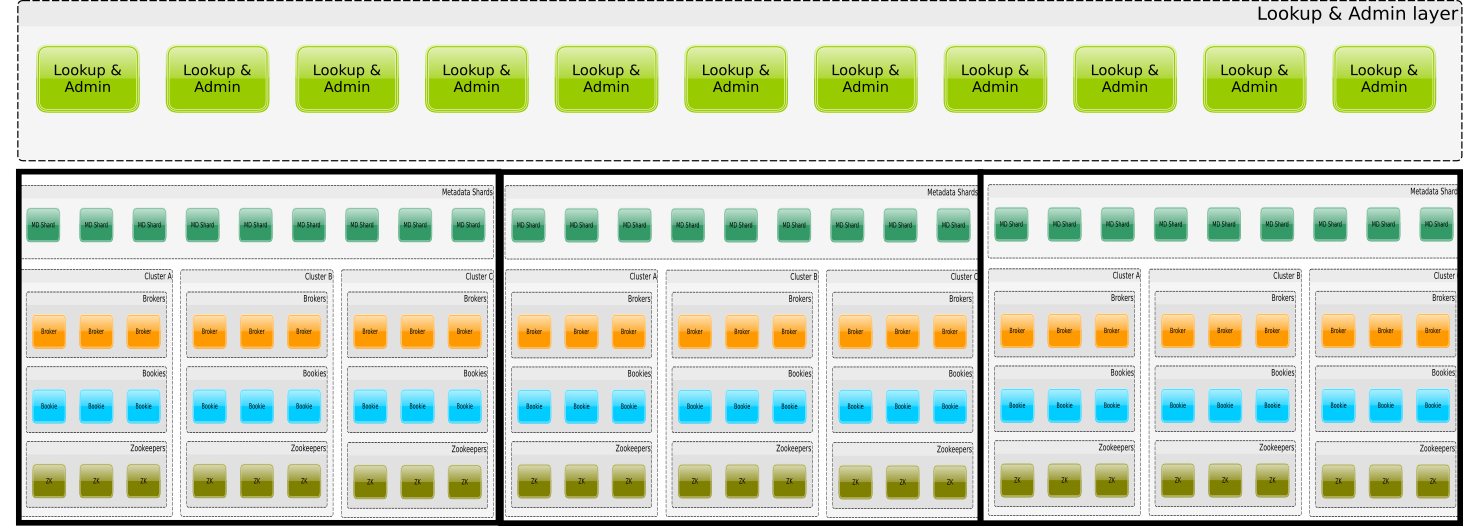
This type of architecture is necessary for large scale cloud service offerings for Apache Pulsar.
It is out of scope of this blog post how to solve geo-replicated architectures and configurations. The presented high level architecture is expected to cover a specific geographical region where there’s low latency access between nodes. There would be a need to have a high level architecture to replace the existing “global zookeeper” type of configuration recommendations and cover features such as “PIP-136: Sync Pulsar policies across multiple clouds” but implemented with the new metadata architecture. Multi-regional configuration of Pulsar requires functionality which we haven’t been covering in this blog post.
Metadata shard
The metadata shard is a deployable runtime component that could be deployed as a Kubernetes pod within a Kubernetes stateful set or in other types of deployments, it would be a single process. The component is stateful from the perspective of containing persistent state that operates as the database for the Metadata. The metadata shard itself contains lower level components which are described later and in upcoming blog posts.
Storage model: Events are the source of truth
The high level idea of storing the state is to use an event log which is stored to the filesystem. It would be an event sourced model where the events are the source of truth. Besides the event log, there would be a RocksDB view of the events. There could be indexes in RocksDB to query the read model that is built from the events. In this way, it could be seen as a CQRS type of solution.
Each metadata shard would have 3 replicas: 1 leader and 2 followers. This is to ensure high availability in the case of failures and when the system is maintained. Each replica would be put into separate upgrade domains. Raft would be used to replicate the state between the shards. Raft also contains leader election as part of it. Changes would be made on the leader replica for each shard. The initial idea is to use Apache Ratis as the Raft and event log implementation.

A metadata shard is a runtime component containing multiple lower level components:
- topic shard inventory
- tenant shard inventory
- namespace shard inventory
- topic controller
- cluster load manager
- broker load manager
The inventory components provide RPC services that handle commands for creating, updating and deleting topics, tenants and namespaces. The component will emit an event and persist it. Since it’s an event source model, the consistency model will be around persisted events. The exact form of RPC is not decided. One possibility would be to leverage RSocket for asynchronous event based RPC or message passing. That is an implementation detail that could be decided later and experimented in the PoC. One of the reasons to use RSocket would be to have proper non-blocking asynchronous backpressure support.
Persisted events can be replicated to other components. The main replication model for replicating state from the metadata shard is in an event sourced way. The event log is the source of truth, and the component that is tracking state changes will be eventually consistent with the changes in the metadata shard.
Some of the metadata consistency issues could be handled in the event log based replication model in a very scalable way. Let’s say that if we were to provide guarantees of consistency for a topic or namespace policy change, the metadata shard could track the current metadata consumers that are synchronizing the metadata changes using the event log replication solution. The way to track this would be to have a RPC call (or event notification) for informing the shard of the position in the event log where the consumer is caught up. A metadata change is fully effective when all consumers of the data have caught up.
This type of model is a different way to handle cache expiration. Instead of thinking of caches, I think it’s more productive to focus on state replication and how can sufficient state consistency be solved for each use case.
For a lot of topic, tenant and namespace policy changes, it might be fine that the state takes effect asynchronously and eventually. However when the user wants to wait until the change is effective, there’s usually a specific reason for this and the APIs should support both use cases. The problems with metadata inconsistency in the current Pulsar architecture was handled in one of the previous blog posts. The goal would be to have an explicit way to express the consistency model and provide a way to achieve strong consistency.
Q: How does the lookup component locate the correct metadata shard for the topic?
This is a very low level detail and this answer might be a bit cryptic. Please ask follow-up questions if this is not understandable.
The metadata shard is located using a hash function. The lookup has multiple steps and isn’t a direct mapping from topic name to a shard. The reason for this is that we would want to support future use cases of renaming and moving topics. This logic won’t be exposed to Pulsar clients. The lookup request comes to any lookup component and it can handle the lookup in the most efficient way.
The high level idea of the mapping:
- map tenant name to internal tenant ID
- first map name to shard id using a hash function. (This level could also handle the usecase of isolating tenant names from other accounts in a multi-tenant system and allow names that don’t need to be globally unique.)
- lookup the internal tenant ID from the shard
- cache and subscribe to future changes from the source shard
- map namespace to internal namespace ID
- first map tenant ID + namespace name to shard id using a hash function
- lookup the internal namespace ID from the shard
- cache and subscribe to future changes from the source shard
- map topic to internal topic ID
- first map tenant ID + namespace ID + topic name to shard id using a hash function
- lookup the internal topic ID from the shard
- cache and subscribe to future changes from the source shard
An internal ID can be mapped to a shard without additional lookups.
This model allows renaming the topic later. In that case, the name -> internal ID mapping would be handled on the other shard, but the topic internal ID would be handled in the former location. The reason for this is that once there’s an internal ID, it directly points to a specific shard where the changes could be made.
The RPC calls could be implemented in a way where the shard would reply with an error response containing the internal topic ID which would include the information of the actual location of the shard when the topic doesn’t exist on the same shard as where the name maps to. The topic ID would be on the same shard in cases where the topic wasn’t renamed or moved from the original location. The extra lookup hop would be eliminated in most cases, since renaming and moving topics from original locations is an exceptional case.
The extra hops for tenant and namespace ids could be eliminated by broadcasting tenants and namespaces on all shards. However, this shouldn’t be necessary since the caching will eliminate extra hops for most cases.
Q: How do topics get assigned efficiently to brokers when topics are handled individually?
There’s no need to assign topics to brokers unless there are connected producers or consumers. One benefit of the new architecture is that idle topics won’t be active on any brokers. In the current Pulsar architecture, all topics in a namespace bundle get activated when any topic gets an active producer or consumer. This detail might require a different approach for maintenance tasks such as data retention so that old data would get periodically deleted. That is something that could be handled on the topic controller. Handling data retention for idling topic bundles is already an uncovered gap in the existing Pulsar architecture.
To the question itself: individual assignment will be efficient when there is no additional communication overhead in assigning one or many topics at a time to the broker. The assumption is that it’s possible to make the solution handle batching when it’s useful and streaming approaches to replicate state and handle assignments. Topics will be assigned to brokers on-the-fly when clients connect.
The load managing and balancing solution should be based on some type of resource allocations. Before assigning work to a broker, the topic controller would request the cluster load manager a quota for new topic allocations. The topic controller would periodically request more assignment quotas from the cluster load manager. The benefit of this approach is that the topic controller can go ahead and assign topics to brokers without additional coordination overhead. The assignment quotas could be based on historical statistics of the topics are explicitly set quotas for topic message rate and bytes rate. The cluster load manager would interact with broker load managers in the metadata shard layer to adjust how assignment quotas will be spread out with the updates to actual load. The broker load managers could themselves take action when load should be reduced on an overloaded broker.
Multi-cluster support for isolating topics in more advanced ways than current broker isolation
The topic assignment could have additional rules like tags which are used to isolate topic assignments. Creating a topic will be different from a topic assignment. When a topic is created, it gets assigned to a cluster in a permanent way. The multi-cluster support can be used for multiple reasons:
- isolating topics in more advanced ways than current broker isolation
- balancing topics across multiple isolated Pulsar brokers+bookies+zookeepers clusters
- phasing out clusters
- similar to Blue-Green deployment PIP-188
- could support also migrating existing topic messages
The multiple cluster support could be used to balance the number of topics across multiple broker+bookie+zookeeper clusters, or it could be used in a way where there’s an empty spare cluster waiting until the previous cluster to be filled has reached a certain level of utilization. This type of solutions could be used to manage the capacity for very large deployments.
There could also be support for something similar (or even reusing) Blue-Green deployment PIP-188 to migrate workloads from an old cluster to a new one.
The topic name and id isn’t directly coupled to a cluster in the new architecture, and this opens up more possibilities. The benefit of phasing out old clusters periodically, is to keep the cluster clean and operational. This is ensured by refreshing clusters completely by phasing out old clusters. With cloud infrastructure this is a feasible approach. It also works as a form of garbage collection and could be used as a way to scale down cluster resources. When a cluster is empty, all persistent storage can be discarded.
Storing the managed ledger metadata in the metadata shard layers would enable doing the migration across clusters while retaining data offloaded to tiered stored. It’s also possible that cluster phase out could be done in the managed ledger layer in a more non-intrusive way. Existing data could be copied to the target cluster while supporting a seamless and transparent migration across clusters, one topic at a time.
Summary of Part 1
- This blog post presented a high level architecture for scaling Pulsar to 100 million topics and beyond.
- The high level entities in this architecture were described.
- Several models to operate and manage large multi-tenant cloud deployments were also presented.
- This is a very early raw draft and it’s not perfect.
- The next part will continue describing the high level architecture and go more in details how the availability challenge of moving topics across brokers could be solved in the new architecture.
Stay tuned for the next part!
Related Posts
- Scalable distributed system principles in the context of redesigning Apache Pulsar's metadata solution
- Rearchitecting Apache Pulsar to handle 100 million topics, Part 4
- Rearchitecting Apache Pulsar to handle 100 million topics, Part 3
- Rearchitecting Apache Pulsar to handle 100 million topics, Part 2
- A critical view of Pulsar's Metadata store abstraction
- Pulsar's namespace bundle centric architecture limits future options
- Pulsar's high availability promise and its blind spot
- How do you define high availability in your event driven system?
- Correction: This blog is not about Apache Pulsar 3.0
- Possible worlds for Apache Pulsar 3.0 and making that actual